Qu’est-ce que c’est ?
IRIS est un outil d’analyse de textes. Il convertit les termes contenus dans ceux-ci en liens hypertextes qui renvoient à des informations utiles pour les comprendre et les traduire le mieux possible.
Quel est son but ?
IRIS cherche à motiver les cosnautas à consulter des termes médicaux difficiles qui sont souvent négligés. Nous ne recherchons pas dans le dictionnaire chaque vocable dont la compréhension et la traduction s’avèrent difficiles. En effet, souvent, nous sous-estimons la complexité de termes qui se ressemblent dans les langues source et cible, ou nous ignorons leur polysémie ou leur variation en fonction du contexte. Les termes compliqués qui n’en ont pas l’air ne sont pas rares. Souvent, ces mots sont peu compris et mal traduits, et pourtant, ils figurent dans les ressources de Cosnautas. Comment pouvons-nous savoir si une unité lexicale apparemment simple, mais sur laquelle nous ne penserions jamais à demander de l’aide, présente une difficulté ? Rien de plus facile : en analysant le texte de départ avec IRIS.
IRIS met en valeur le contenu des ressources auxquelles on accède rarement par le biais des requêtes depuis les moteurs de recherche correspondants. Cet outil démontre que les moteurs ne sont pas la seule façon fructueuse d’accéder aux sources lexicographiques. IRIS est une alerte contre les difficultés insoupçonnées.
Comment fonctionne cet outil ?
C’est très simple. La première étape consiste à soumettre à IRIS le texte que l’on souhaite analyser. Cela peut être fait de trois manières différentes : en l’écrivant directement dans le champ prévu, en le copiant depuis le document source et en le collant dans le champ, ou encore en le chargeant à l’aide du bouton « Charger un document ».
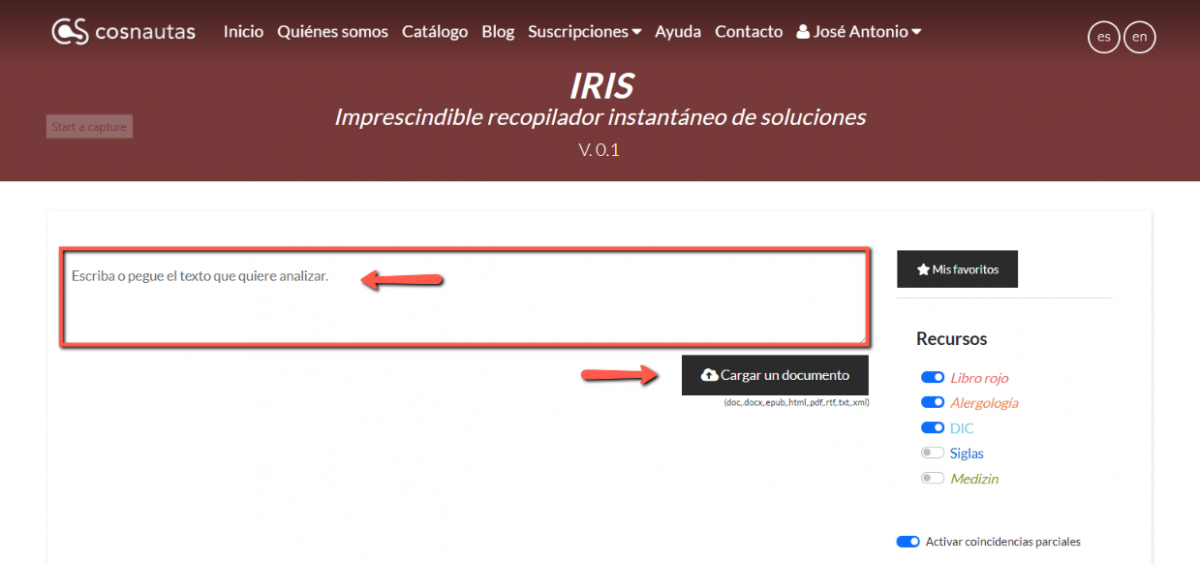
IRIS applique automatiquement une série d’algorithmes de recherche et compare le texte avec les listes d’entrées de toutes les ressources sélectionnées. Ensuite, l’outil met en valeur les correspondances et les transforme en liens hypertextes vers les entrées où ces termes figurent.

Il suffit à l’utilisateur/rice de cliquer sur n’importe quel terme souligné pour qu’une boîte de dialogue s’ouvre. Celle-ci indique quelles ressources contiennent littéralement le terme, avec une correspondance exacte (marquée en bleu) et quelles entrées, qui peuvent appartenir à différentes ressources, comprennent des informations potentiellement utiles (correspondances partielles, marquées en vert).

En cliquant sur un terme, l’article dans lequel figurent les propositions de traduction s’ouvre dans un nouvel onglet.
Fonctions secondaires
- Sélectionner des ressources : Par défaut, IRIS est programmé pour travailler avec la paire de langues anglais-espagnol. De ce fait, les ressources activées sont uniquement le Libro rojo, le Diccionario de investigación clínica et Alergología e inmunología. Cependant, l’utilisateur/rice qui travaille avec d’autres paires de langues peut ajouter ou éliminer des ressources à l’aide de l’outil de sélection. Les algorithmes de recherche fonctionnent également avec l’allemand et l’espagnol ; et à l’avenir, ils prendront en charge d’autres langues.
- Activer les correspondances partielles : IRIS incorpore deux formes de reconnaissance de correspondances. La première, absolue, est toujours active et rassemble les articles lexicaux qui ont littéralement pour titre la portion du texte qui coïncide. La seconde, partielle, identifie également les entrées dont les titres diffèrent d’un certain nombre de caractères par rapport au texte analysé. Naturellement, cette deuxième forme de reconnaissance, quoiqu’elle puisse être utile, donne souvent des résultats faussement positifs, et de ce fait, elle peut être désactivée.
- Favoris : IRIS enregistre tous les termes qui ont été marqués comme favoris, afin que l’utilisateur/rice puisse y revenir facilement.
- Mode confidentiel : Dans la configuration par défaut, l’IRIS collecte des informations statistiques sur les termes les plus consultés et externalise la conversion des documents chargés vers un portail spécialisé qui lui permet de travailler avec de nombreux formats. Cependant, quand le mode confidentialité est activé, l’outil cesse d’enregistrer les informations statistiques et la conversion est réalisée localement sur le serveur de Cosnautas. Cela limite les formats disponibles, mais accroît le contrôle exercé sur le document.

- Ignorer ce terme : L’outil permet à l’utilisateur/rice de décider s’il/elle souhaite que certains termes cessent d’apparaître comme soulignés, parce qu’il/elle les connaît ou les a déjà consultés, afin d’obtenir un texte plus dégagé.