What is IRIS?
IRIS is a
text analysis tool that converts terms into hyperlinks to useful information to
understand and translate them in an optimal way.
What is it used for?
IRIS aims
to motivate cosnauts to review difficult medical terms that are frequently
overlooked. Not all terms of intricate understanding and translation are to be
found in a dictionary. Frequently, we underestimate the complexity of similar
words in the source and target languages, or we are unaware of polysemy and
contextual variation. There are many terms that are more difficult than they
seem, terms that are frequently barely understood and badly translated, and
despite this they are listed in Cosnautas resources. How can we know if a
seemingly simple lexical unit, one that we would never normally seek help for,
might pose some difficulty? The solution is very easy: by analysing the source
text with IRIS.
IRIS highlights resource content that would otherwise rarely be found by other
web searches and demonstrates that such searches are not the only means to find
useful lexicographical resources. IRIS alerts against unforeseen difficulty.
How does it work?
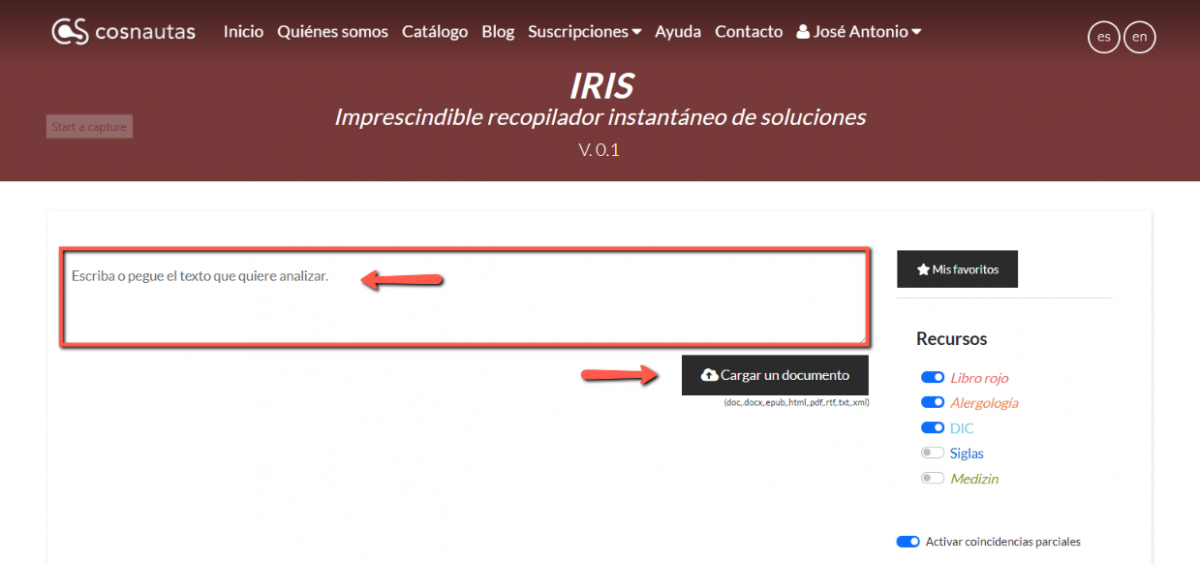
The tool is very simple. The first step consists of sending the text that you want to analyse to IRIS, which can be done in three different ways: writing it directly in the text field, copying it from the source document and pasting it in the field, or uploading a document by clicking on the corresponding button.
IRIS
automatically applies a series of search algorithms and contrasts the text with
corpora from all the selected resources. Next, it highlights all the matches
and inserts hyperlinks to the corresponding related entries.

The user
then simply clicks on any marked term to open a pop-up window showing the
resources that literally list the word, with exact matches highlighted in blue,
as well as other resources that might hold possibly useful information or
partial matches, highlighted in green.
Upon
clicking on any of these terms, a new tab is opened with the article showing
the possible translations.
Secondary functions
- Selecting resources. By default, IRIS is programmed
to work with an English-Spanish language pair, and therefore only the Libro
rojo, the Dictionary of Clinical Research, and Allergology
and Immunology are activated resources. However, users who work with
other language pairs can add or remove resources in the selection setting.
The search algorithms work equally well in German and in Spanish, and in
the future they will also do so with other languages.
- Activating partial matches. IRIS provides two types of
match recognition, one being absolute and always active in compiling the
lexical articles that are literal to the portion of the matched text,
while the other is partial and identifies entries with headings that may
vary within a certain number of characters with respect to the analysed
text. Naturally, this second form of recognition, though usually useful,
often produces false positives, and for that reason it can be deactivated.
- Favourites. IRIS stores all the terms
marked as favourites so that the user may easily return to them.
- Private mode. Using the default
configuration, IRIS gathers statistical information about the most
searched terms and externalizes the conversion of uploaded documents to a specialized
portal that works with numerous formats. However, when private mode is
activated, no statistical information is collected and the document
conversion is made locally in the Cosnautas server, which limits the
available formats but increases the control the user has over the
document.
